Knowledge Interface between Humans and AI
The World
Throughout history, people have constructed knowledge collaboratively as a public good, and the internet has made it accessible to everyone.
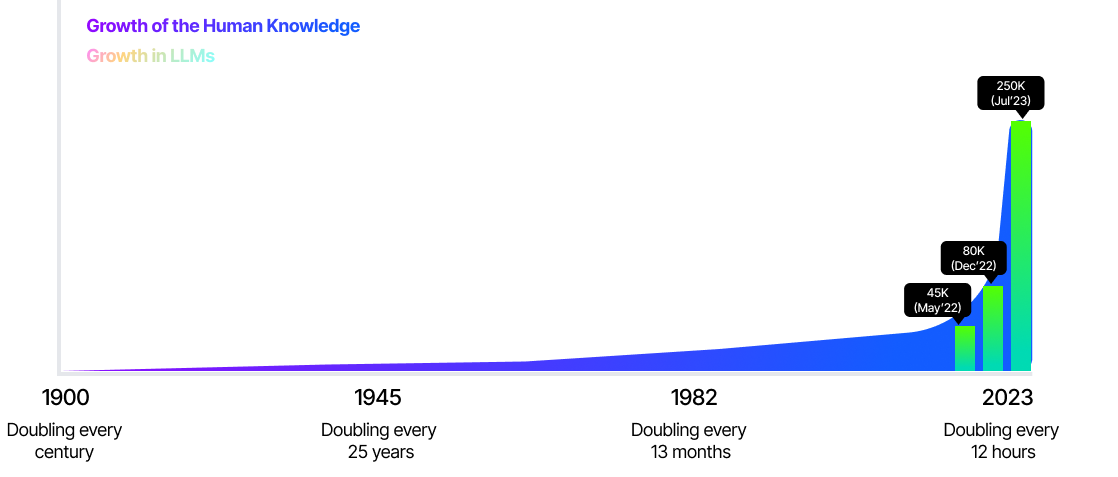
Thanks to the Internet, we are approaching an era where knowledge doubles every 12 hours. For the sake of comparison, in 1900, human knowledge had been expanding roughly every century. By the end of 1945, this pace had accelerated to every 25 years.
Wikipedia stands as a prime example of this collaborative development of knowledge. Now, in the era of AI, we are witnessing a paradigm shift.
Developers' adoption of AI models grows daily, i.e., 250,000+ models on Hugging Face, fueling the demand for ever-evolving knowledge to be integrated with LLMs.
Despite the exponential growth of AI, there remains a significant gap in accessible, collaborative platforms for knowledge sharing and retrieval.
Training new LLMs or fine-tuning them with fresh knowledge is insufficient to keep LLMs up with the expanding human knowledge.
The landscape of information has continually evolved. In the digital age, the internet revolutionized the dissemination of knowledge, transforming paper documents into web pages. Google emerged as a dominant force, indexing websites and curating content, establishing a well-understood digital creation and discovery cycle.
Now, we stand on the brink of another transformative era with LLMs. LLMs are redefining the paradigms of information creation, access, and sharing. As we shift, traditional websites are transitioning to Public RAG models, where AI intricately interfaces with information.
In a pivotal moment in the annals of internet history, we find ourselves at a crossroads regarding the status of knowledge as a democratized public asset. We stand on the brink of an era where knowledge, once freely accessible and shared, risks becoming a centralized commodity.
This new reality threatens to transform knowledge into a private, costly resource accessible only to a privileged few.
It's a time when open science, collaboration, and unrestricted knowledge sharing are more vital than ever. These practices have long fueled human innovation, breaking down barriers and fostering groundbreaking discoveries.
The story of our future hinges on maintaining and enhancing access to global knowledge. It's not only a matter of principle but a foundational necessity for future generations. The ability for humans to share and retrieve the vast expanse of world knowledge freely must remain a fundamental right.
In this way, we can ensure that the democratization of knowledge, a principle so integral to our success, continues to guide us into a future marked by inclusivity, advancement, and open connectivity.
Core Problems
Cost of Knowledge:
- Storing identical knowledge in multiple isolated AI memories and repeatedly conducting technical processes in closed environments hinders collaboration, innovation, and feedback mechanisms.
- This inefficient and costly cycle can be broken by creating a collaborative and open knowledge space. Here, human efforts would shift from redundant repetition of processes to focusing more on innovation and acceleration.
- The absence of Open RAG and barriers to contributing knowledge slows down progress.
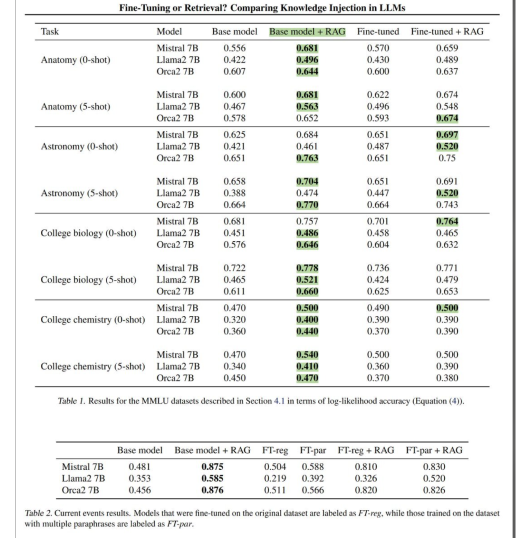
RAG (Retrieval-Augmented Generation) is more effective at incorporating knowledge into LLMs compared to unsupervised fine-tuning (USFT). It has also been observed that using RAG on its own outperforms the combination of RAG and fine-tuning.
- Limited Reach:
- Free speech fosters a healthy environment for creating and sharing knowledge. To ensure free speech thrives, we need an environment where individuals can express themselves effortlessly.
- Today, contributing global knowledge to LLMs is a fragmented and challenging process for most internet users, rendering it more accessible to AI developers rather than the billions of people using the internet.
- unSAFE:
- Siloed and centralized AI knowledge could pave the way for harmful entities to create manipulative one-to-one persuasion strategies, making accountability challenging to ascertain.
- We are moving towards a world where various agents will continuously influence human judgment, making it easier to manipulate our decisions on critical issues such as elections, wars, and existential challenges.
- In the post-LLM era, AI-generated data is fed into the internet, contaminating the very source we use to train large language models. We need a collaborative knowledge platform for maintaining a clean data pool.
Dria
Dria serves as a collective memory for AGI, where information is stored permanently in a format understandable to both humans and AI, ensuring universal accessibility.
Dria is a collective Knowledge Hub.
Knowledge Hub consists of small-to-medium-sized public vector databases called knowledge.
A knowledge can be created from a pdf file, a podcast, or a CSV file.
Vector databases are multi-region and serverless.
Dria is fully decentralized, and every index is available as a smart contract. Allowing permissionless access to knowledge without needing Dria’s services.
Dria provides:
- An API for knowledge retrieval implementing search with natural language and query.
- A docker image for running local APIs without permission.
Knowledge uploaded to Dria is public and permanent.

DRIA operates as:
- A public RAG model.
- A Serverless and Multi-Region vector database, accessible with natural language and its API, characterized by its massive scalability and low fees.
- A Decentralized knowledge hub, where each vectorDB can be run locally in a permissionless manner.
- A platform enabling searchability of any knowledge.
- An open-source embedding lake.
First Principles
- Every index should be rebuildable with a different indexing algorithm or embedding model using the same knowledge. This is crucial for serving in state-of-the-art retrieval at all times.
- Every piece of knowledge should be accessible without depending on a central authority.
- Uploading quality knowledge to collective memory should be rewarded.
Specs
- Dria supports the following file formats for knowledge creation: PDF, CSV, and audio files for podcasts.
- The indexing algorithms or embedding models can be changed without affecting the existing knowledge structure.
- It implements a reward system for uploading quality knowledge to the collective memory.
Dria supports index types: HNSW, ANNOY
Annoy is static.
HNSW is dynamic.
Vector databases are multi-region; requests are geo-steered. Regions currently include: **
us-east-1
us-west-1
eu-central-1
ap-southeast-1
Dria has no cold start for retrieval.
The benchmark for deep-image-angular-96 with top_n=10, requests sent within the region. QPS wont throttle but performance may reduce after a certain threshold.

Paving the way for open AGI: Core Solutions
1-) Cost of Knowledge at Its Lowest:
Dria modernizes AI interfacing by indexing and delivering the world's knowledge via LLMs.
Dria’s Public RAG Models Democratize knowledge access with cost-effective, shared RAG models.
Today, Dria efficiently handles Wikipedia's entire 23GB database and its annual 56 billion traffic at just $258.391, a scale unattainable by other vector databases.
Dria operates as a Decentralized Knowledge Hub serving multiple regions, offering natural language access and API integration.
Dria supports multiple advanced indexing algorithms and embed models. This offers the flexibility to seamlessly switch between algorithms or embed models using the same data, ensuring consistently state-of-the-art retrieval quality.
2-) Contributing is easy and incentivized for everyone:
- Dria’s zero technical mumbo jumbo approach allows everyone to contribute knowledge to LLMs:
Dria’s Drag & Drop Public RAG Model effortlessly transforms knowledge into a retrievable format with an intuitive drag-and-drop upload feature.
As a permissionless and decentralized protocol, Dria creates an environment where knowledge uploaders can earn rewards for the value of their verifiable work:
Users worldwide can contribute valuable knowledge with permissionless access to shared RAG knowledge for LLMs, applications, and open-source developers.
If other participants query the knowledge and produce valuable insights into AI applications, the users will earn rewards for their verifiable contributions.
Users can then use these rewards to upload or query more knowledge into the collective memory.
3-) Safe, Trust Minimized, and Open Collaboration:
Anyone can run RAG models locally through smart contracts, enabling permissionless access to world knowledge.
Dria stores all of the world's knowledge into a public ledger called Arweave, a decentralized storage network designed to offer a platform for the permanent storage of data.
Arweave's main value proposition is that it allows users to store data permanently. Once something is uploaded to the Arweave network, it's intended to be stored forever without the risk of data loss or degradation.
Full persistence ensures accountability against manipulative AI technologies that proliferate during elections, wars, and existential crises. Communities can reevaluate AI knowledge, establishing transparent mechanisms for safeguarding against manipulation.
Another use case centers around deepfakes; by uploading detected deepfakes to DRIA, users and applications worldwide can query suspicious videos to ascertain their authenticity.
What’s coming (soon)?
The Librarian
Search through all public knowledge with a single query. The Librarian is a model of models. A macro index to propagate a query to related knowledge and perform retrieval.
Multi-Modal Rag
Search through multiple knowledge with a single query enabling more flexible retrieval.
Verifiability
It’s essential for Dria to verify that:
- Knowledge is uploaded by humans
- Uploaded data/information is created by humans.
- Vector databases are populated with embeddings the owner claims to use.
- Credentials for knowledge are valid.
Native Clients
Python and JS clients for:
- Creating contracts/vector databases
- Inserting single/batch data
- Remove items
- Query with vector
- Search with natural language
- Fetch items
- Re-build index
Performance improvements:
- Faster index building
- Higher QPS without performance degradation
- Lower latency
- More file formats
- 10+ regions
Permissionless, multi-party contribution
Allowing multiple parties to contribute to a single knowledge without compromising the control over the content. This feature will enable a dynamic and collaborative way to enrich the public vector databases. Insertion won’t depend on Dria services but will be fully executed on the contract level.
Contributing this article to the Collective AI Memory:
We are contributing this article to Dria, where it will be accessible to everyone, can be run locally, and will live forever.
High-Level Product Roadmap